一次内存dump排查记录
初步分析
最近一个应用一直提示获取连接超时,找运维dump内存后分析原因。
在开始前就猜到了大概率是因为某个sql超长时间执行导致连接不释放,导致连接池占用满了。
项目使用的tomcat-jdbc连接池。
直接查oql
1 | select t from org.apache.tomcat.jdbc.pool.PooledConnection t |
得到返回的20池连接对象。点开池连接后可以看到对象详细信息。
对象org.apache.tomcat.jdbc.pool.PooledConnection是由org.apache.tomcat.jdbc.pool.ProxyConnection所持有。
一直往上查,查到org.apache.tomcat.jdbc.pool.StatementFacade$StatementProxy。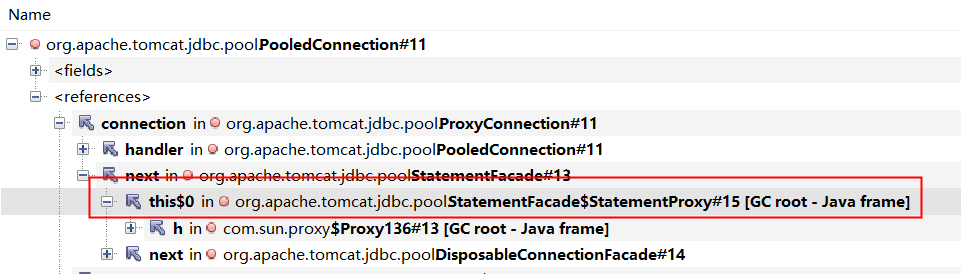
打开改对象后,可以查到改连接正在执行的sql。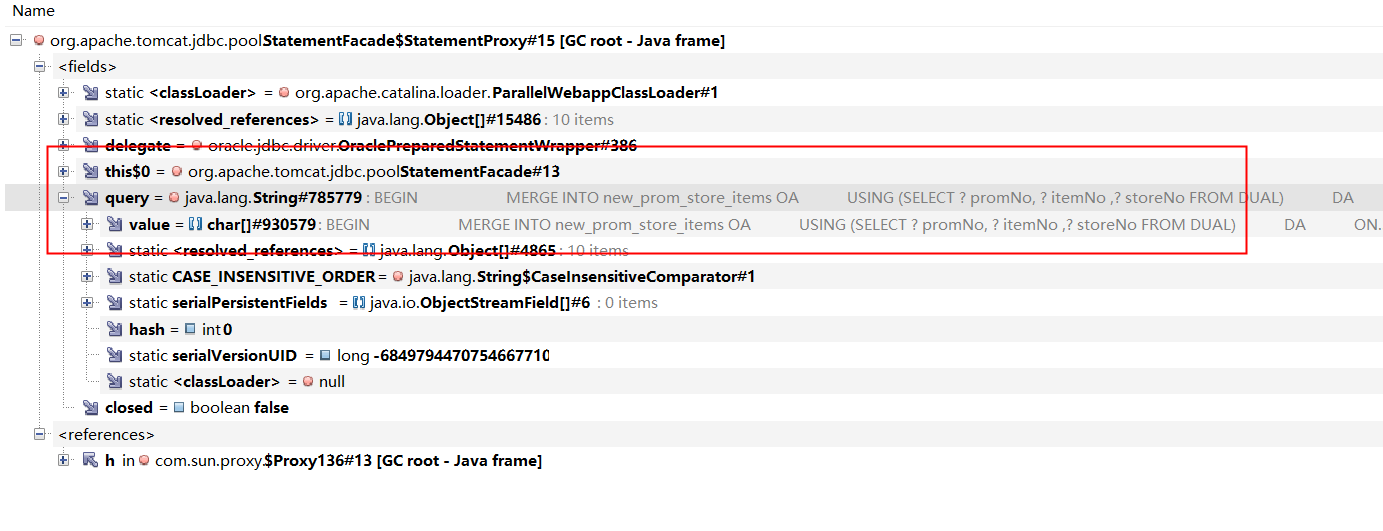
直接使用oql查询
1 | select t from org.apache.tomcat.jdbc.pool.StatementFacade$StatementProxy t |
可以查到正在执行的和待执行的sql。
通过分析连接池时间戳可以看出sql开始执行时间。
源码分析
我们是有配置连接清理的,如果连接未正常被回收,理论上应该被清理。
通过分析线程栈可以找到驱动执行的地方如下: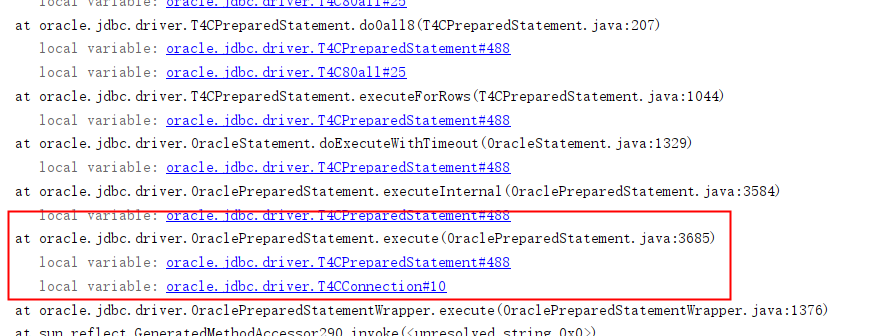
找到代码所在如下: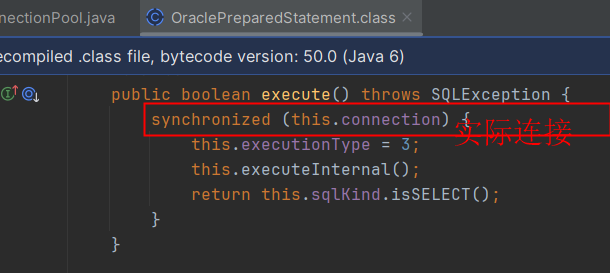
在执行sql时,会先锁住时间数据库连接,然后执行对应操作。
锁住的对象是oracle.jdbc.driver.PhysicalConnection
对于清理线程org.apache.tomcat.jdbc.pool.ConnectionPool.PoolCleaner清理,可以通过线程栈查看调用
查看最终清理源码如下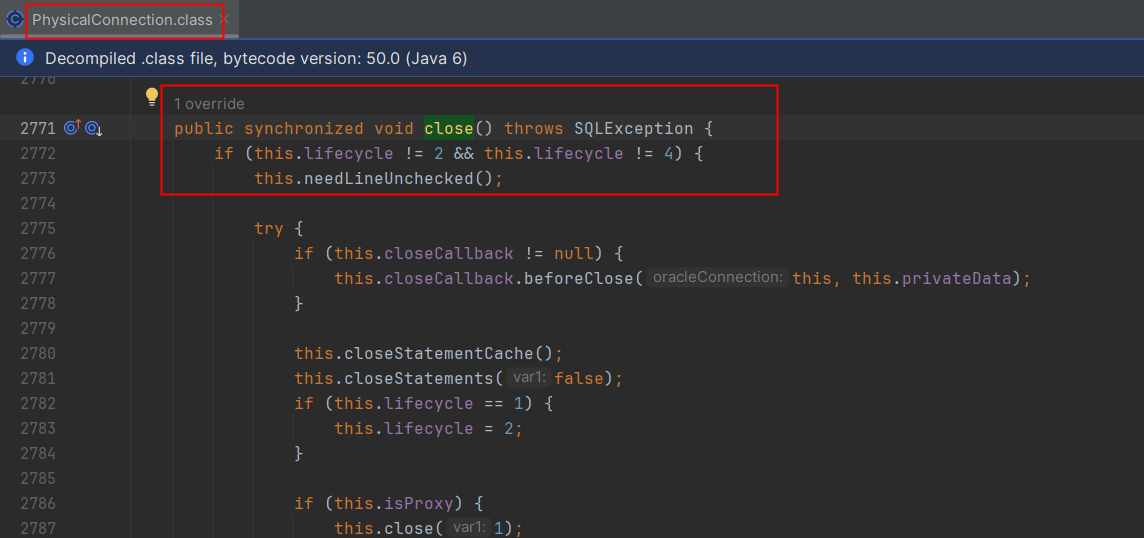
做close的时候会去获取真实连接PhysicalConnection的锁,前面所知在执行sql的时候会锁住连接,直到执行完后释放sql,清理的时候也需要获取锁导致一直在等待,清理线程也卡住。
理下流程,现有某个sql超长时间执行,清理线程触发清理后,因为获取不到锁导致清理线程也卡住了。
通过分析数据库连接时间戳发现该sql执行了几天还未执行完,未定位到是什么原因导致sql异常执行超长时间卡住,是否事务未关闭或者其他数据库原因,因为项目已经重启没法查看连接状况。
解决办法
上面最开始找到了执行超长的sql,把卡住的sql导出后,发现文件小的有几百kb,大的有1M多,可能因为里面有很多空白行。
原本逻辑是通过foreach拼接了sql,导致生成了一个巨大的sql。
现在先改为单sql批量提交看是否可以解决这个问题,改为单sql在性能上好像不如一个大sql,这需要后续做测试才能肯定。