业务逻辑
主要是通过商品查询商品相关的活动信息,流程如下
1、查询商品相关信息(DB)
2、查询商品对应活动相关信息(DB)
3、查询商品在指定门店是否被排除(DB)
4、赠品库存校验(HTTP)
5、限购校验(HTTP+Redis)
6、数据封装返回
业务逻辑流程比较清晰
初次优化
对数据操纵做异步处理,使用线程池,对数据异步处理后,统一汇总,返回数据
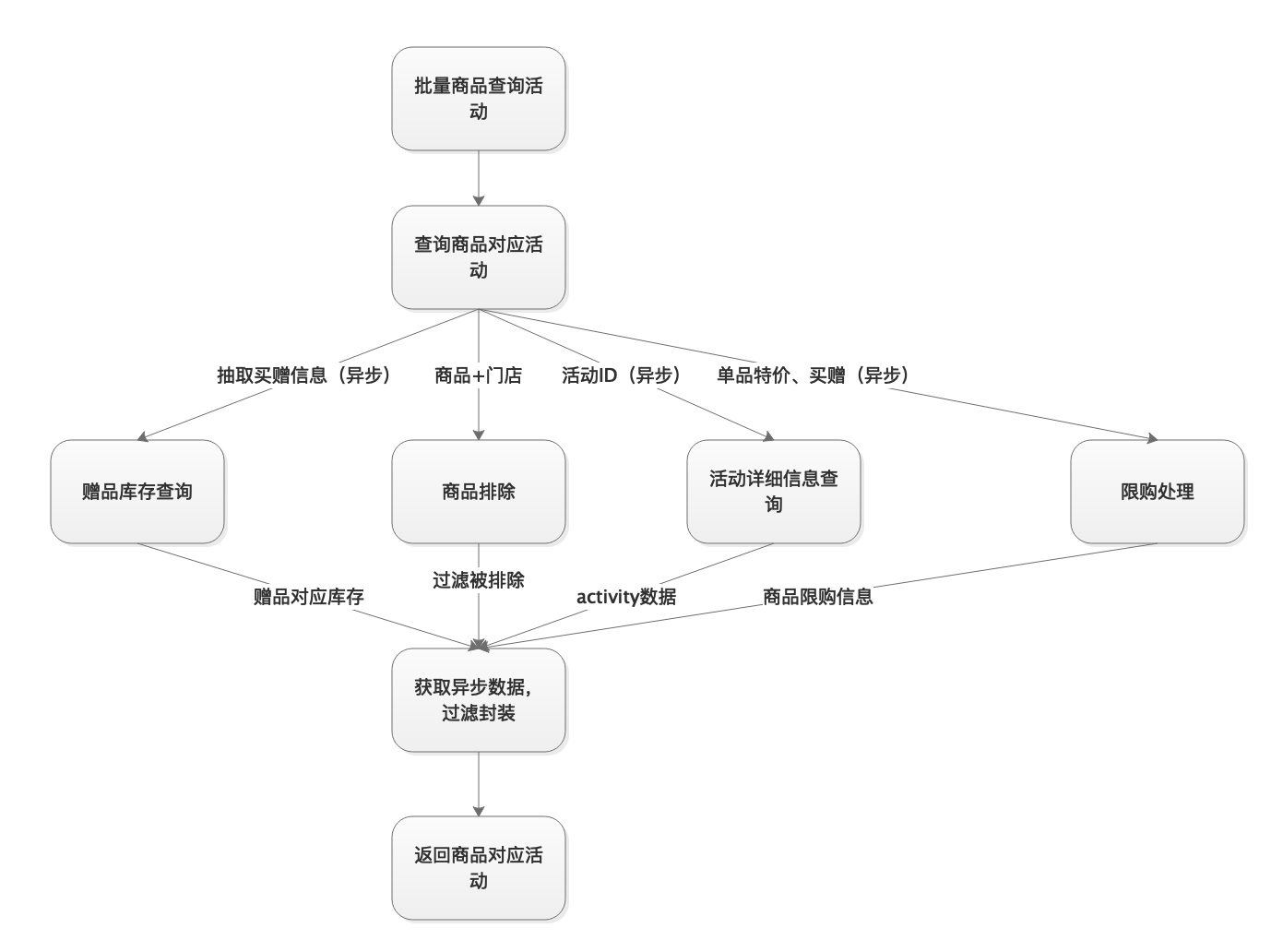
对数据做异步优化如上所示。
把其中3个流程通过线程池做异步处理,当前线程处理相关数据,之后对数据进行汇总对数据进行封装返回。
加入缓存二次优化
缓存设计为一、二级缓存。一级缓存为本地缓存速度快、缓存时间短、数量少,项目部署都是多机部署,所以一级缓存对于不同服务器数据有冗余。二级缓存未Redis远程缓存速度比本地缓存慢、存储时间相对长、数量大。如果一、二级缓存穿透流程会流转到DB逻辑,如初次优化逻辑处理。
数据流程如下:
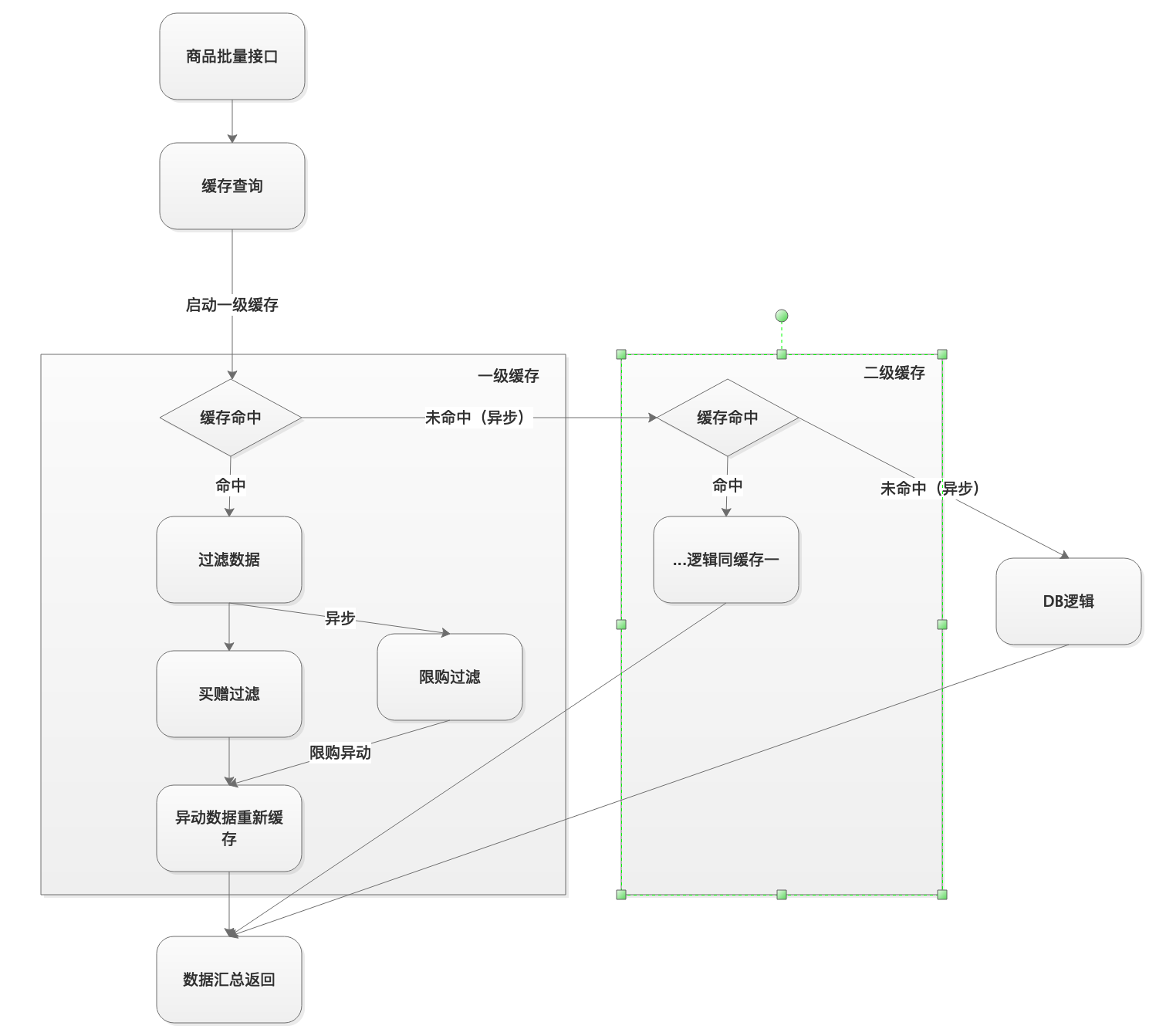
批量数据处理,如果一级缓存命中,走正常逻辑,未命中数据流转到下一级。二级缓存如果未命中,数据流转到下一级。一二级缓存未命中逻辑处理逻辑一致,都是对数据进行过滤以及重新缓存。如果某级全部未命中,那么流转到下一级走同步方法,不需要走线程池异步处理。
缓存问题
缓存可能会存在几个问题
缓存雪崩
如果缓存出现大批量过期,那么会导致大批量数据流转到DB,数据库压力大增,可能会导致数据库崩溃。
在设置缓存的时候,加入了随机值,避免同一时间大量缓存失效。
缓存穿透
在查询数据的时候,如果有很多key查询不到数据,不做处理,这样会导致大量没数据的key走到DB层,这样接口的TPS会比较低,那么需要对不存在的数据一样进行缓存,缓存内容为空数据,避免缓存穿透
缓存击穿
当缓存过期后,再次查询缓存会查询不到数据,这样数据会走到DB。这样的问题,需要对缓存数据进行更新。
设计一个多生产者批量插入,单消费者可以批量处理的逻辑。
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
|
public class ConcurrentLink<T> {
private Node<T> head;
private Node<T> tail;
private AtomicInteger headi = new AtomicInteger(0);
private AtomicInteger taili = new AtomicInteger(0);
private final Object addLock = new Object();
private ReentrantLock lock = new ReentrantLock();
private final static Integer THRESHOLD_VAL = 10000000;
public ConcurrentLink() {
Node<T> empty = new Node<>(null, null);
head = empty;
tail = empty;
}
public int add(Collection<T> list) {
if (list.isEmpty()) {
return 0;
}
Node<T> thead = null;
Node<T> next = null;
for (T t : list) {
if (thead == null){
thead = new Node<>(t, null);
next = thead;
continue;
}
next.next = new Node<>(t, null);
next = next.next;
}
try {
lock.lock();
tail.next = thead;
tail = next;
} finally {
lock.unlock();
}
taili.addAndGet(list.size());
return list.size();
}
public List<T> poll(int num) {
int min = Math.min(size(), num);
if (min < 0) {
return Collections.emptyList();
}
List<T> res = new ArrayList<>();
for (int i = 0; i < min; i++) {
Node<T> next = head.next;
head.next = null;
head.item = null;
head = next;
res.add(head.item);
}
headi.addAndGet(min);
if (taili.get() > THRESHOLD_VAL) {
taili.addAndGet(-THRESHOLD_VAL);
headi.addAndGet(-THRESHOLD_VAL);
}
return res;
}
public int size() {
return taili.get() - headi.get();
}
private static class Node<T> {
private T item;
private Node<T> next;
Node(T item, Node<T> next) {
this.item = item;
this.next = next;
}
}
}
|
在设计缓存的时候,在存储的value上加上缓存失效时间字段,一级缓存为7分30秒50000条数据,二级缓存字段设置失效时间为10分钟,实际存入Redis时间较长为10分钟+1分钟+60内随机秒,当一级缓存失效好,数据流转到二级缓存,在二级缓存处判断缓存是否即将失效(3分钟),因为实际缓存时间较长,所以数据还是会正常走缓存获取,只是对于即将失效的数据,会把数据存入之前设计的链表中,在项目启动的时候,会启动一个线程每次从缓存中批量获取数据,然后对数据同步到缓存。因为实际缓存时间较长,所以在同步的这个时间段内,数据还是会走正常缓存。